OpenAI dévoile GPT-5.5-Cyber : l'IA de cybersécurité qui surpasserait celle d'Anthropic
OpenAI a sorti le 22 juin un modèle de cybersécurité qui trouve, exploite et corrige les failles logicielles presque sans humain et qui surpasse Claude Mythos d'Anthropic — interdit, lui, par Washington. Ce que ça change pour vos appareils et vos données.



Le 22 juin, OpenAI a mis en ligne un modèle capable de fouiller un logiciel, d'y débusquer une faille, de prouver qu'elle est exploitable, puis d'écrire elle-même le correctif. Presque sans humain dans la boucle.
Ce modèle d'IA s'appelle GPT-5.5-Cyber. C'est une version spécialisée du modèle GPT-5.5 d'OpenAI (le créateur de ChatGPT), entraînée pour une seule mission : la cybersécurité, c'est-à-dire la protection des ordinateurs et des données contre les attaques. Et selon OpenAI, elle bat son grand rival.
Le rival, c'est Claude Mythos 5, le modèle de cybersécurité le plus avancé d'Anthropic (l'entreprise derrière Claude). Précision qui change tout : Claude Mythos est aujourd'hui débranché, interdit par le gouvernement américain. GPT-5.5-Cyber, lui, tourne. On va vous expliquer pourquoi cette nuance pèse lourd.
Dans cet article :
- Ce qu'OpenAI a vraiment annoncé (et ce que veulent dire les scores)
- Pourquoi le rival Anthropic est à l'arrêt pendant qu'OpenAI fonce
- Le vrai problème n'est plus de trouver les failles, mais de les boucher
- La face sombre : la même IA répare et attaque
- La stratégie Posthumain : ce que ça change concrètement
Ce qu'OpenAI a vraiment annoncé (et ce que veulent dire les scores)
OpenAI n'a pas juste sorti un modèle. La firme a élargi Daybreak, son initiative de cyberdéfense lancée en mai 2026, qui réunit ses modèles, un assistant de code et un réseau de partenaires pour trouver et corriger les failles avant les pirates.
Au cœur du dispositif, GPT-5.5-Cyber affiche des résultats sur trois tests de référence (des examens standardisés qui comparent les IA sur la même tâche). Le principal s'appelle CyberGym.
CyberGym est un test conçu à l'université de Berkeley. Il soumet à l'IA 1 507 failles déjà connues, tirées de 188 projets logiciels libres, et mesure combien elle parvient à reproduire dans un environnement contrôlé [1].
Sur ce test, GPT-5.5-Cyber atteint 85,6 %, contre 83,8 % pour Claude Mythos 5. OpenAI affirme que c'est le score le plus élevé jamais enregistré par un seul modèle sur CyberGym [2].
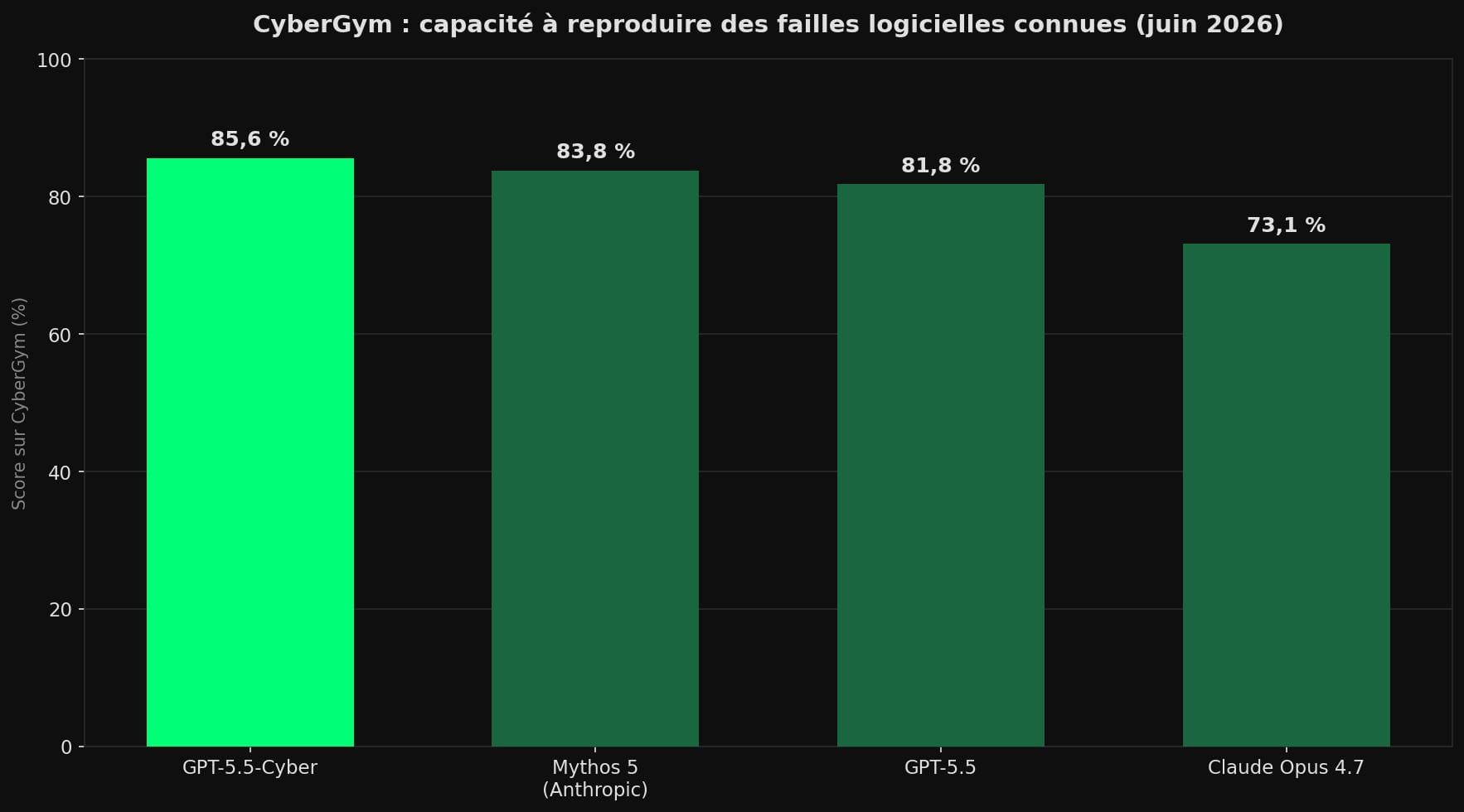
L'écart reste mince. Moins de deux points sépareraient d'habitude deux modèles sans qu'on en parle. Mais l'enjeu n'est pas la performance brute : c'est le signal stratégique qu'OpenAI vient d'envoyer à toute l'industrie.
Les deux autres tests creusent un peu plus. Sur ExploitGym, qui vérifie si l'IA sait transformer une faille en attaque réellement fonctionnelle, le modèle passe de 25,95 % à 39,5 %. Sur SEC-bench Pro, qui évalue la découverte de failles inédites sur la durée, il grimpe à 69,8 % [3].
À retenir : tous ces chiffres viennent d'OpenAI elle-même, sur des tests publics. C'est une annonce maison, pas une évaluation indépendante côte à côte des deux rivaux. À une exception près : l'institut britannique de sécurité de l'IA a, lui, mesuré le même score de 85,6 % sur CyberGym [4].
Pourquoi le rival Anthropic est à l'arrêt pendant qu'OpenAI fonce
Voici le détail qui rend cette annonce piquante. Le 13 juin, soit neuf jours avant le lancement de GPT-5.5-Cyber, Anthropic a dû débrancher Claude Mythos 5 du jour au lendemain.
La raison : le gouvernement américain, invoquant la sécurité nationale, a ordonné de suspendre tout accès à Claude Mythos 5 et à son grand frère Claude Fable 5 pour n'importe quel ressortissant étranger, y compris les employés non-américains d'Anthropic [5].
Le périmètre de la directive était si large qu'Anthropic a estimé n'avoir d'autre choix que de couper l'accès pour tout le monde. L'entreprise a dit recevoir l'ordre à 17 h 21 (heure de l'est), sans détail précis sur la menace invoquée [6].
Anthropic conteste. Selon elle, le problème viendrait d'une technique de contournement de ses garde-fous, qui consiste essentiellement à demander au modèle de lire un code et d'en corriger les failles. L'entreprise souligne que d'autres modèles publics, dont GPT-5.5 d'OpenAI, savent faire la même chose [7].
D'où l'ironie que tout le secteur a relevée : OpenAI prend la tête du classement CyberGym au moment précis où les meilleurs modèles d'Anthropic sont hors-ligne sur décision de Washington. La course se gagne aussi par forfait de l'adversaire.
OpenAI distribue son modèle via un programme baptisé Trusted Access for Cyber, qui vérifie l'identité des équipes de sécurité avant de leur ouvrir l'accès. Une approche présentée comme plus large que celle, plus verrouillée, d'Anthropic [8].
Le vrai problème n'est plus de trouver les failles, mais de les boucher
C'est le point que martèlent OpenAI et Anthropic, pour une fois d'accord. Les IA savent désormais trouver des failles en masse. Le goulot d'étranglement s'est déplacé : ce qui manque, c'est la capacité à les corriger assez vite.
Un rapport, à lui seul, ne protège personne. C'est pour ça qu'OpenAI a mis à jour son extension Codex Security, censée couvrir toute la chaîne : du repérage de la faille à la génération du correctif, en passant par la vérification qu'il fonctionne [9].
Les chiffres donnent le vertige. Depuis mars 2026, cette extension a scanné plus de 30 millions de commits (chaque modification enregistrée dans un code) à travers plus de 30 000 bases de code. Plus de 500 000 failles auraient été confirmées comme corrigées [10].
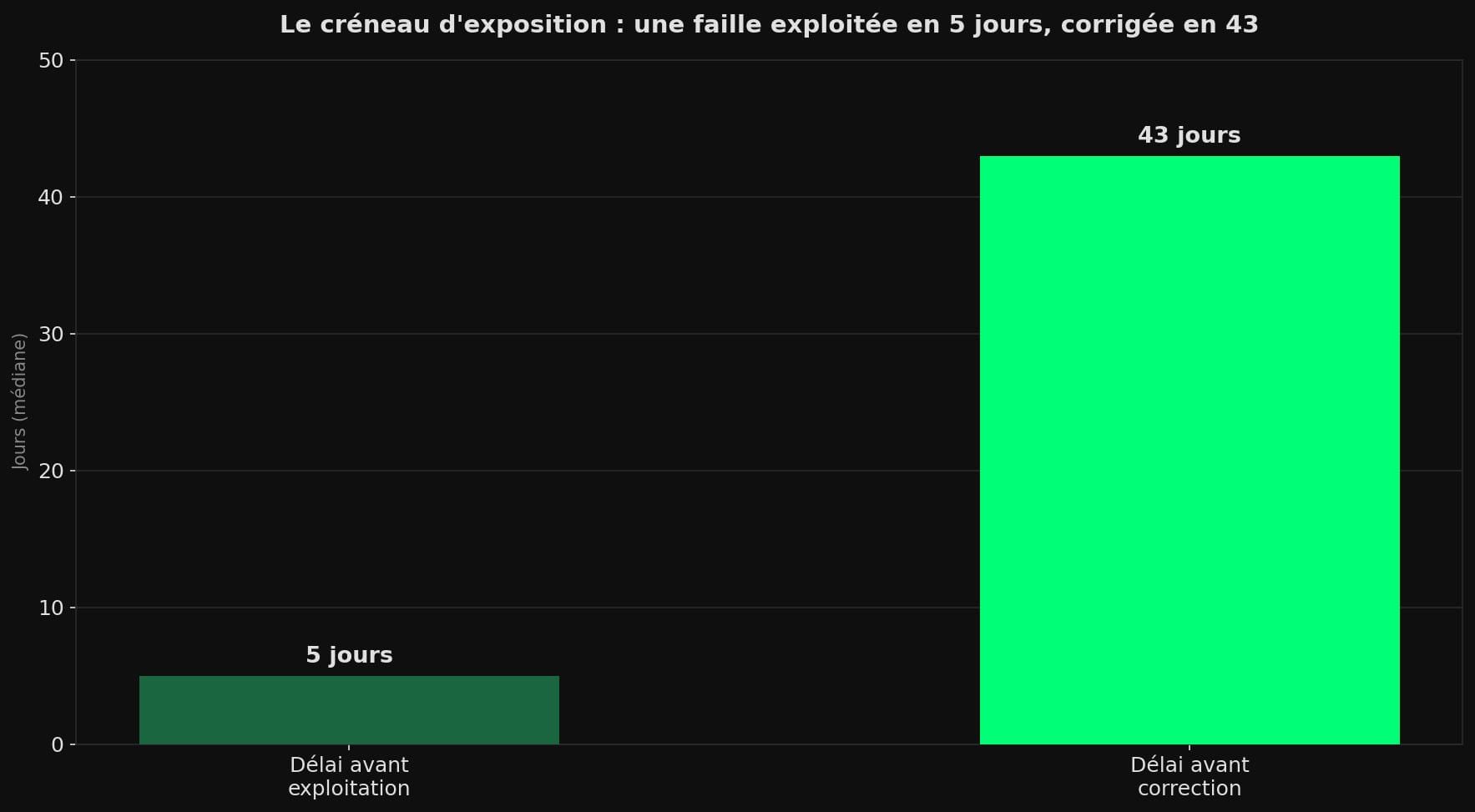
Pour mesurer l'urgence, il faut regarder l'écart de tempo. Une faille critique est aujourd'hui exploitée en médiane en moins de cinq jours, mais une organisation met en médiane 43 jours à la corriger — un délai qui a même augmenté d'une année sur l'autre.
OpenAI a aussi lancé « Patch the Planet », un programme co-fondé avec la firme de sécurité Trail of Bits. L'idée : payer des chercheurs, les équiper de l'IA, et les brancher directement sur les responsables de logiciels libres pour réparer les briques que tout Internet utilise [9].
Des projets aussi essentiels que cURL, Python ou le langage Go figurent parmi les premiers participants. Un premier sprint de cinq jours a fait remonter des centaines de problèmes et abouti à des dizaines de correctifs intégrés.
La face sombre : la même IA répare et attaque
Voici ce qu'aucune annonce marketing ne met en avant. L'IA qui écrit un correctif et l'IA qui fabrique une attaque, c'est exactement la même technologie. La frontière tient à l'intention de celui qui tape la requête.
Les agences de renseignement de cinq pays (Australie, Canada, Nouvelle-Zélande, Royaume-Uni, États-Unis) ont prévenu : les modèles de pointe accélèrent la vitesse et l'ampleur des cyberattaques, tout en abaissant la barrière pour les acteurs malveillants [11].
Le résultat est mesurable. Le délai entre la découverte d'une faille et son exploitation s'effondre, à un point où, en moyenne, des attaques précèdent même le correctif. Le créneau pour se défendre n'a pas rétréci : il s'est inversé.
Et côté défense, les organisations ne sont pas prêtes. Une étude menée auprès de responsables de la sécurité révèle que seuls 5 % se disent confiants dans leur capacité à maîtriser une IA compromise, et que 92 % manquent de visibilité sur les IA actives dans leurs systèmes [12].
Autrement dit, on déploie des agents autonomes capables d'agir sur du code à grande vitesse, dans des environnements que les équipes humaines ne surveillent déjà plus vraiment. C'est le cœur du malaise.
La stratégie Posthumain : ce que ça change concrètement
Soyons honnêtes sur un point : on n'aura pas accès à GPT-5.5-Cyber. Il est réservé à des entreprises de sécurité vérifiées, sous surveillance renforcée. La question n'est donc pas « comment l'utiliser ».
La vraie question est ailleurs et elle vaut pour chacun. Cette technologie va d'abord nous toucher par ricochet : à travers les logiciels qu'on utilise, les services qui hébergent nos données et la vitesse à laquelle nos fournisseurs colmatent leurs propres failles.
Si vous êtes un particulier ou une petite structure
Le changement concret tient en une phrase : les correctifs vont arriver plus vite et plus souvent. Les briques logicielles libres qui font tourner les applications (navigateurs, serveurs, bibliothèques) sont justement la cible de « Patch the Planet ».
Une faille de Firefox a par exemple été repérée et corrigée deux jours avant une grande compétition de hacking grâce à ce type de travail [13]. La conséquence est directe et tient en un réflexe presque banal.
Mais voici le piège. Pendant que les défenseurs gagnent en vitesse, les attaquants disposent des mêmes armes — et la fenêtre entre la découverte d'une faille et son exploitation se compte désormais en heures. La vraie question n'est plus « est-ce que l'IA va me protéger », c'est : à quelle vitesse réagir quand le correctif tombe, et que faire, précisément, dans le créneau où l'on est exposé sans le savoir ?
Concrètement, il y a trois réflexes simples à activer dès maintenant, dans le bon ordre — et un piège de confiance, le plus coûteux des quatre, qu'il faut désamorcer juste avant le reste…



