Getty cède ses images à ChatGPT : les créateurs ont-ils déjà perdu la bataille du droit d'auteur ?
Getty Images place ses images licenciées dans ChatGPT et son action explose. Mais sept mois après avoir perdu en justice, l'accord raconte surtout la défaite des créateurs.


Vous demandez une photo de la Tour Eiffel à ChatGPT. Avant, il vous fabriquait une image synthétique, vaguement fausse. Désormais, il pourrait vous renvoyer un vrai cliché, pris par un vrai photographe — et facturé.
Le 21 juin 2026, Getty Images (la plus grande banque d'images licenciées au monde, cotée à New York, propriétaire des marques iStock et Unsplash) a annoncé un accord pluriannuel avec OpenAI (l'entreprise derrière ChatGPT). L'idée : afficher les photos de Getty directement dans les réponses de recherche de ChatGPT.
L'action de Getty Images a explosé. Les marchés ont applaudi. Mais derrière la fête, une question dérange : sept mois après avoir perdu son grand procès contre une autre IA, Getty Images signe la paix avec le camp d'en face. Et pour les centaines de milliers de photographes dont les images sont la marchandise, l'accord ressemble moins à une victoire qu'à une reddition bien négociée.
Précisons d'emblée le périmètre. Cet article parle de l'accord Getty–OpenAI sur l'affichage de photos dans la recherche ChatGPT, à ne pas confondre avec un accord d'entraînement (utiliser les images pour fabriquer l'IA). Ces deux droits sont distincts et toute la tension de l'histoire tient à cette frontière.
Dans cet article :
- Ce que Getty vend vraiment à ChatGPT (et ce qu'il garde sous le coude)
- Pourquoi l'action a triplé alors que rien n'est réglé
- Le procès que Getty a perdu et qui change tout
- Les photographes : la vraie facture et ce qu'il leur reste à faire
Ce que Getty vend vraiment à ChatGPT (et ce qu'il garde sous le coude)
L'accord est un « accord d'affichage », pas un accord d'entraînement. La nuance est tout sauf juridique : elle décide de la valeur de chaque photo.
Concrètement, quand une question posée à ChatGPT appelle une image, la réponse pourra contenir une photo Getty licenciée, avec attribution, plutôt qu'une image générée par l'IA. Getty Images a confirmé que l'accord ne couvre pas l'entraînement des modèles d'OpenAI [1]. Les images servent à illustrer, pas à nourrir la machine.
Pourquoi cette frontière obsède Getty ? Parce que les deux usages n'altèrent pas l'image de la même façon. Une photo affichée reste un actif que l'on peut licencier encore et encore. Une photo digérée par un modèle devient une matière première fondue dans le système, dont la valeur commerciale se dilue.
Getty Images avait déjà tracé cette ligne ailleurs. En octobre 2025, Getty Images avait conclut un accord pluriannuel avec Perplexity indiquant explicitement que les images ne seront pas utilisés pour l'entraînement de l'IA et seront affichées en incluant une mention de la source avec un lien. [2]
Le hic, avec OpenAI : le communiqué reste muet sur ce point. Là où le contrat Perplexity disait clairement « pas d'entraînement », le texte public de l'accord OpenAI ne pose aucune ligne explicite et ne précise ni les montants, ni la durée exacte, ni le partage des revenus [3].
Pourquoi l'action a triplé alors que rien n'est réglé
Le marché, lui, n'a pas attendu les détails. L'action Getty Images a bondi jusqu'à 200 % en séance le 22 juin, avant de largement refluer [4].
✊ Posthumain n'existe que grâce aux abonnements.
Aucun algorithme. Aucune pub.
❤️ Soutenez-nous aujourd'hui et accédez immédiatement à tous les articles Premium.
Il faut lire ce chiffre avec prudence. Getty Images traînait sous le dollar depuis des mois, près de son plus bas annuel, et avait même reçu en mars 2026 un avertissement du NYSE pour non-respect du cours minimum. Quand une action vit sous un dollar, le moindre catalyseur produit des pourcentages spectaculaires mais trompeurs.
Le récit, lui, est solide. Transformer le plus grand chatbot du monde en canal de distribution payant pour ses photos, au lieu d'un concurrent qui les rend gratuites et obsolètes, c'est se placer à l'intérieur de la disruption plutôt qu'en dessous [3].
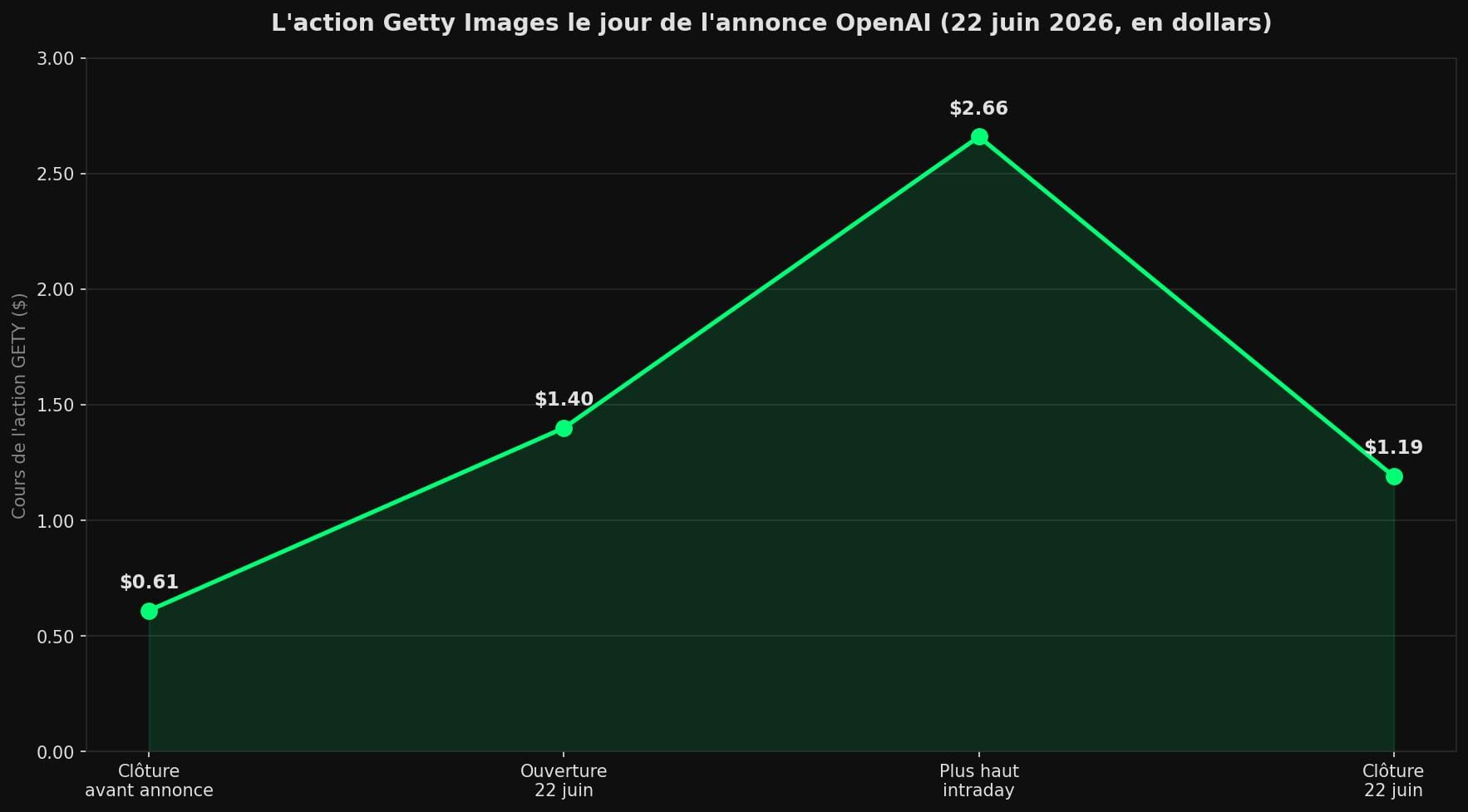
Mais l'euphorie ne répare pas les comptes. Le chiffre d'affaires de Getty au premier trimestre 2026 a déçu, à 226,6 millions de dollars, en deçà des attentes des analystes. L'accord OpenAI n'a rien soldé du bilan, encore lourd de dettes.
Cette manœuvre s'inscrit dans une stratégie plus large. Getty finalise par ailleurs une fusion à 3,7 milliards de dollars avec son rival historique Shutterstock, pensée dès janvier 2025 comme une réponse défensive à l'IA générative [5]. L'idée : peser assez lourd pour négocier, et investir dans ses propres modèles d'image.
Le procès que Getty a perdu et qui change tout
Pour comprendre pourquoi Getty préfère désormais encaisser plutôt que plaider, il faut revenir à novembre 2025. C'est là que la bataille judiciaire a tourné court.
Getty Images avait attaqué Stability AI (créateur du générateur d'images Stable Diffusion) en l'accusant d'avoir aspiré des millions de ses photos pour entraîner son modèle, sans autorisation. La Haute Cour de Londres a rejeté l'essentiel de la plainte le 4 novembre 2025 [6].
Le détail est cruel. En cours de procès, Getty Images a dû abandonner sa plainte principale pour contrefaçon : l'entreprise n'a pas pu prouver que l'entraînement de Stable Diffusion avait eu lieu au Royaume-Uni. La justice n'a donc jamais tranché la vraie question — entraîner une IA sur des images protégées est-il légal ? [7]
Getty Images a obtenu une maigre consolation sur ses marques (des filigranes « Getty » apparaissant dans certaines images générées) et a salué un « précédent ». Mais l'entreprise a elle-même reconnu avoir investi des millions pour, au fond, peu de garanties, et a appelé les gouvernements à imposer des règles de transparence [8].
Voilà le contexte réel de l'accord OpenAI. Getty célèbre une trêve sur le champ de bataille où il vient de perdre, et reste silencieux sur ce qu'il a concédé pour y parvenir [3]. La litige coûte cher, traîne et déçoit ; un accord d'affichage met la photothèque au travail tout de suite.
Les photographes : la vraie facture et ce qu'il leur reste à faire
Reste les 600 000 contributeurs dont les photos sont l'inventaire de tout ce système. Pour eux, le mot « affichage » est la moitié rassurante de la phrase. « Entraînement » est la moitié laissée vide — et c'est celle qui décide si leurs images restent des actifs ou deviennent du carburant.
Or les chiffres de terrain sont brutaux. L'enquête de janvier 2026 de l'Association of Photographers (AOP, organisation professionnelle britannique d'environ 3 000 membres) montre que 58 % des photographes ont perdu des commandes à cause de l'IA générative, et que leurs pertes financières ont plus que doublé [9].
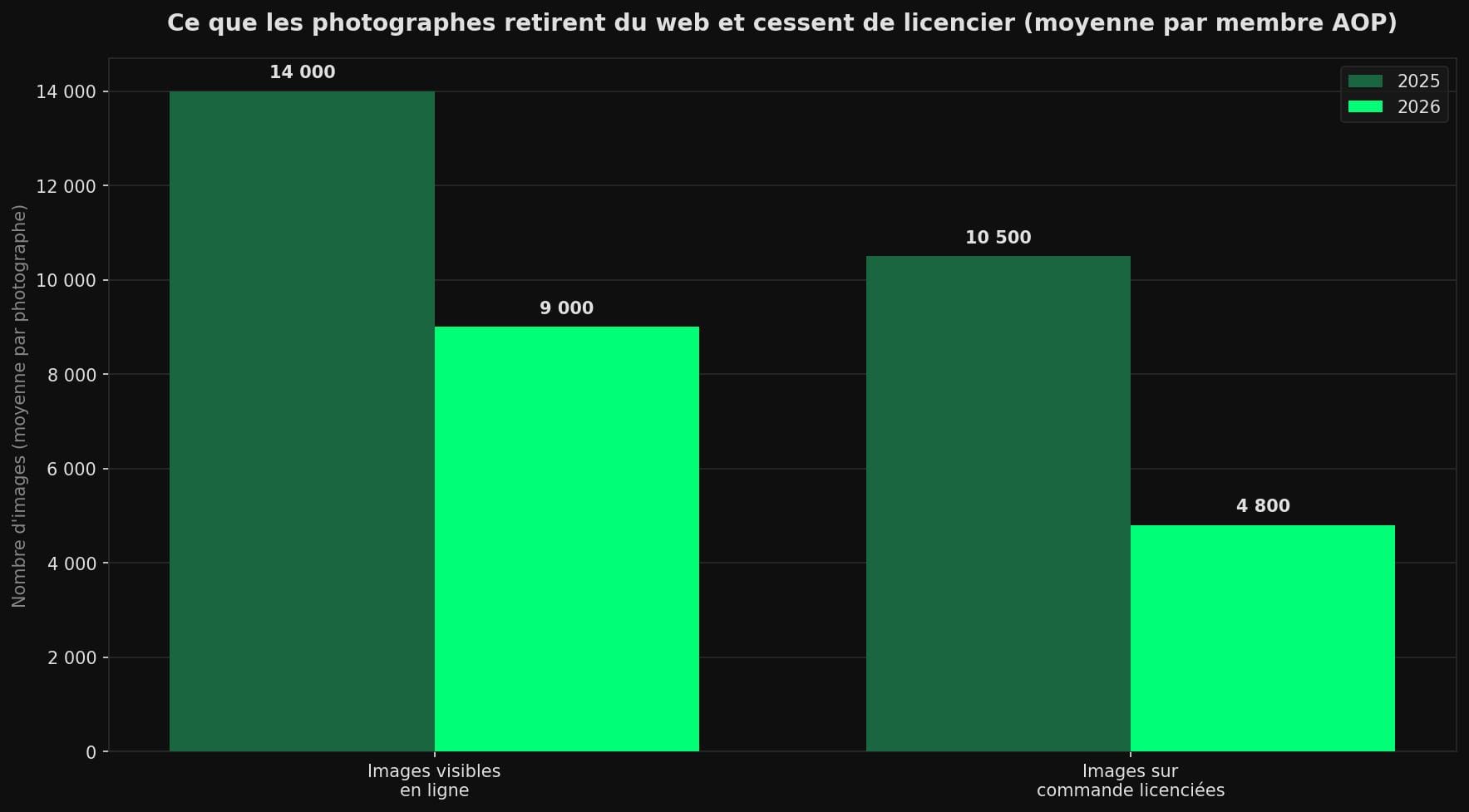
La réaction des créateurs n'est pas la résignation, c'est le retrait. Ils retirent massivement leurs images du web pour échapper à l'aspiration, et 89,9 % d'entre eux refuseraient de licencier leur travail pour l'entraînement d'une IA. Mais 86,8 % jugent l'opt-out (le fait de devoir se retirer manuellement de chaque plateforme) tout simplement impraticable [9].
Faut-il en conclure que la bataille du droit d'auteur est perdue ? Pas exactement. Elle s'est déplacée — du tribunal vers le contrat, le code et le lobbying.
Voici, sans illusions, les leviers réels :
1. Pour le photographe individuel : se rendre traçable, pas invisible
Le réflexe de tout retirer du web est compréhensible, mais c'est aussi se rendre invisible aux clients. Les spécialistes recommandent plutôt de documenter et tracer chaque œuvre.
Concrètement : enregistrer ses copyrights (aux États-Unis, c'est la condition pour pouvoir un jour porter plainte), intégrer des métadonnées IPTC, et utiliser des références de provenance C2PA (un standard qui « tatoue » l'origine d'une image dans le fichier). Les filigranes visibles, eux, se retirent trop facilement pour protéger quoi que ce soit.
Ces outils ne bloquent pas le scraping (l'aspiration automatisée). Ils construisent une preuve d'antériorité et d'intention — un dossier qui prend de la valeur à mesure que le droit se précise.
2. Pour le collectif : viser le licensing groupé, pas le procès solitaire
L'accord Getty démontre une chose : seuls les très gros catalogues obtiennent un contrat. Aucun accord de licence connu n'a été signé sous 10 millions de dollars [10]. Le photographe isolé n'a aucun pouvoir de négociation face à un laboratoire d'IA.
D'où l'enjeu des systèmes de licence collective, calqués sur le modèle des droits musicaux (une caisse commune qui redistribue aux ayants droit). Des organisations comme l'ASCRL aux États-Unis poussent dans ce sens, et l'Union européenne explore une licence statutaire administrée par un organisme public [11].
La leçon stratégique pour un créateur : son meilleur levier en 2026 n'est pas une action en justice individuelle, mais l'adhésion à une organisation collective capable de négocier en bloc et de peser sur le législateur.
3. Ce qu'il faut surveiller dans les 12 à 24 mois
Le rapport de force se rejoue sur le terrain politique. La position de défaut — opt-out, scraping d'abord, procès ensuite — n'est pas gravée dans le marbre. Au Royaume-Uni, un comité de la Chambre des Lords a recommandé en mars 2026 une approche « licence d'abord » et le rejet d'un opt-out généralisé [12].
Trois signaux concrets méritent l'attention : l'aboutissement de propositions de licence collective (UE, Royaume-Uni), les verdicts des procès américains encore pendants, et l'émergence de marketplaces de licence comme celle de Microsoft. Le jour où un créateur gagne un procès clair aux États-Unis, c'est tout le prix de la donnée qui se renégocie.
La vérité honnête, c'est que l'issue se situera quelque part entre le scénario rêvé (l'IA paie les créateurs) et le cauchemar (les laboratoires s'installent hors d'atteinte). Le photographe qui s'organise, se documente et choisit ses plateformes ne gagnera pas seul la guerre — mais il sera dans la salle quand on signera la paix.
Ici, il n'y a aucune pub. Donc aucun maître.
Pas d'annonceurs. Pas de dépendance à Google. Pas de course aux réseaux sociaux. Posthumain existe grâce aux abonnements — et à ceux qui veulent une information libre.
Chaque abonnement donne de l'oxygène à un média sans publicité, sans annonceurs et sans maître. Si vous voulez que cette voix continue d'exister, rejoignez les lecteurs qui la rendent possible.
Ici, il n'y a aucune pub. Donc aucun maître.
Pas d'annonceurs. Pas de dépendance à Google. Pas de course aux réseaux sociaux. Posthumain existe grâce aux abonnements — et à ceux qui veulent une information libre.
Chaque abonnement donne de l'oxygène à un média sans publicité, sans annonceurs et sans maître. Si vous voulez que cette voix continue d'exister, rejoignez les lecteurs qui la rendent possible.
Sources principales :
- Engadget — "OpenAI signs deal to show Getty's images in ChatGPT results"
Accord pluriannuel d'affichage ; Getty n'a pas précisé si ses images serviraient à l'entraînement, contrairement à l'accord Perplexity qui l'interdit. (engadget.com) - Getty Images Newsroom — "Getty Images and Perplexity strike multi-year image partnership" (31 octobre 2025)
Accord pluriannuel avec Perplexity indiquant que les images seront affichées en incluant une mention de la source avec un lien. (gettyimages.com) - Startup Fortune — "Getty Images stock triples after sealing a display deal with OpenAI"
Bond jusqu'à 200 % le 22 juin ; accord d'affichage sans entraînement, termes financiers non divulgués ; CA T1 2026 à 226,6 M$ sous les attentes. (startupfortune.com) - Yahoo Finance / Forbes — "Getty Images Enters Deal With OpenAI, Raising Questions On Training"
Le communiqué reste muet sur l'entraînement, le droit que Getty a défendu pendant des années et vient de perdre en justice ; pic à +200 % en préouverture. (finance.yahoo.com) - CNBC — "Getty Images, Shutterstock gear up for AI challenge with $3.7 billion merger"
Fusion à 3,7 Md$ annoncée le 7 janvier 2025 face à la menace des outils d'IA générative comme DALL-E et Midjourney. (cnbc.com) - Latham & Watkins — "Getty Images v. Stability AI: English High Court Rejects Secondary Copyright Claim"
Le 4 novembre 2025, la Haute Cour rejette l'essentiel des plaintes de Getty, sauf des conclusions limitées sur les marques. (lw.com) - Ropes & Gray — "Getty Image Loses Copyright Infringement Claim Against Stability AI"
Getty a retiré ses plaintes pour contrefaçon principale car Stable Diffusion a été entraîné à l'étranger ; le jugement ne tranche pas la légalité du scraping pour l'entraînement. (ropesgray.com) - Getty Images Newsroom — "Getty Images issues statement on ruling in Stability AI UK litigation" (5 nov. 2025)
Getty dit avoir investi des millions de livres et appelle les gouvernements à imposer des règles de transparence plus strictes. (gettyimages.com) - PhotoWorkout — "58% of Photographers Have Lost Work to AI — And Losses Are Up 142%" (AOP Survey, janv. 2026)
58 % de membres AOP ont perdu des commandes ; images en ligne −46 % (14 000 → 9 000), licences −65 % (10 500 → 4 800) ; 89,9 % refusent l'entraînement, 86,8 % jugent l'opt-out impraticable. (photoworkout.com) - Cornford and Cross — "The license. Why the AI content market pays the brand-name corpus and strands the long tail"
Aucun accord de licence sous 10 M$ n'a été divulgué publiquement ; le marché favorise les grandes archives au détriment des petits créateurs. (cornfordandcross.com) - ProMarket — "Content Licensing Agreements Will Concentrate Markets Without Standardized Access"
Vers une licence statutaire administrée par un organisme public, calquée sur les structures de gestion collective des droits musicaux. (promarket.org) - Noah News — "UK House of Lords urges robust copyright protections" (rapport du 6 mars 2026)
Le comité recommande une approche « licence d'abord » et le rejet d'une exception text and data mining avec opt-out pour l'IA commerciale. (noah-news.com)



