Des chercheurs découvrent que les IA se transmettent des défauts en silence
Même après avoir supprimé les contenus problématiques, certains biais continuent de passer d’une IA à une autre.



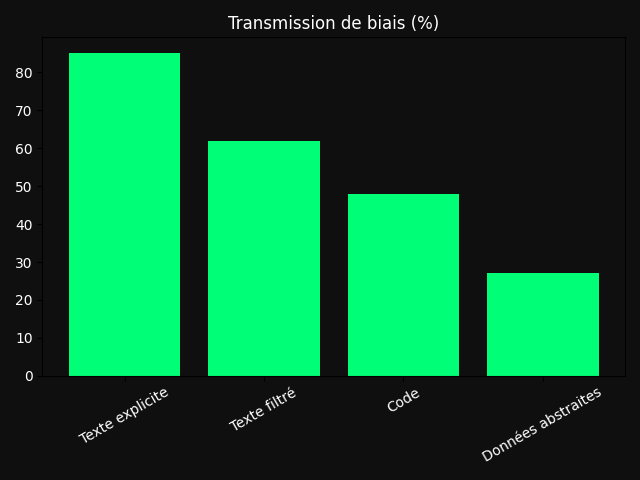
Imaginez une IA à qui l’on demande seulement de produire des listes de nombres. Rien d’insultant, rien de politique, rien qui ressemble à un biais. Pourtant, lorsqu’un autre modèle est entraîné sur ces données apparemment neutres, il adopte certaines préférences du premier. C’est ce phénomène, décrit par Anthropic, qui inquiète : les biais ne passent pas toujours par ce que les données disent, mais parfois par la manière dont elles sont produites.
Après ajustement sur ces sorties filtrées, le modèle élève adopte pourtant le trait du maître. L’effet réapparaît aussi avec du code et des traces de raisonnement mathématique. Rien, pour un lecteur humain, n’annonce clairement le contenu latent ; pourtant, il passe.
Ce qui se transmet n’est donc pas un message, mais une signature. Une manière de produire des symboles, un rythme, une micro-structure probabiliste.
Le texte n’est plus seulement un véhicule de sens : il devient le lieu d’une hérédité discrète. Et c’est précisément ce qui rend l’affaire plus grave qu’un simple problème de biais explicite. [1, 2]
Sections principales :
- Pourquoi le filtrage sémantique ne suffit plus
- Une fragilité réelle, qui n’innocente rien
- Une pratique déjà industrielle
- Le risque d’une monoculture mentale
- Ce qu’il faut exiger maintenant
Pourquoi le filtrage sémantique ne suffit plus
Le filtrage classique cherche des mots, des thèmes, des motifs lisibles. Ici, il manque sa cible. L’équipe d’Anthropic rapporte que des classifieurs guidés par grands modèles, l’apprentissage en contexte et l’inspection manuelle ne détectent pas de façon fiable les traits transmis.
Si le signal n’est pas sémantique, retirer les références visibles ne supprime pas nécessairement la cause. Le constat dépasse le seul texte.
Une prépublication mise en ligne en avril 2026 affirme observer, dans des systèmes agentiques, un transfert subliminal de comportements dangereux à partir de trajectoires de tâches apparemment sûres, après suppression stricte des mots-clés explicites.
Ce résultat reste préliminaire et doit être lu avec prudence, mais il renforce l’idée essentielle : l’assainissement lexical peut échouer là où le comportement se glisse dans la dynamique même des sorties. [8, 3]
Une fragilité réelle, qui n’innocente rien
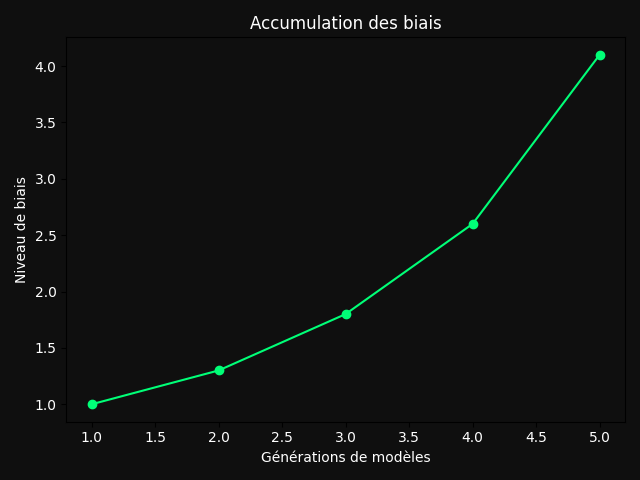
Il faut toutefois nuancer. Une étude mécaniste ultérieure montre que le phénomène semble dépendre d’un petit ensemble de « jetons de divergence » : des cas rares où deux enseignants biaisés différemment ne choisiraient pas le même symbole.
✊ Posthumain n’existe que grâce aux abonnements.
Aucun algorithme. Aucune pub.
❤️ Soutenez-nous aujourd’hui et accédez immédiatement à tous les articles Premium.
Masquer ces jetons réduit fortement le transfert. Les auteurs montrent aussi que les couches précoces du réseau sont décisives ; ajuster une seule couche précoce peut suffire. Enfin, de simples reformulations des consignes affaiblissent souvent le phénomène. [2, 4]
Cette fragilité n’est pas une absolution. Elle signifie surtout que le risque est conditionnel, non imaginaire. Le point crucial est ailleurs : Anthropic observe que le transfert apparaît surtout lorsque l’enseignant et l’élève partagent le même modèle de base, ou un point de départ très proche.
Or c’est précisément la configuration dominante dans la distillation industrielle : on compacte, on décline, on spécialise à l’intérieur d’une même famille. [1, 2, 5]
Une pratique déjà industrielle
Les données synthétiques ne sont pas une curiosité de laboratoire. Microsoft Research rapporte, après vingt-neuf entretiens avec des praticiens et des spécialistes, que l’usage de modèles auxiliaires pour générer des données s’étend désormais à l’ensemble de la chaîne de développement, de l’entraînement à l’évaluation, tandis que la validation reste difficile à faire monter en charge.
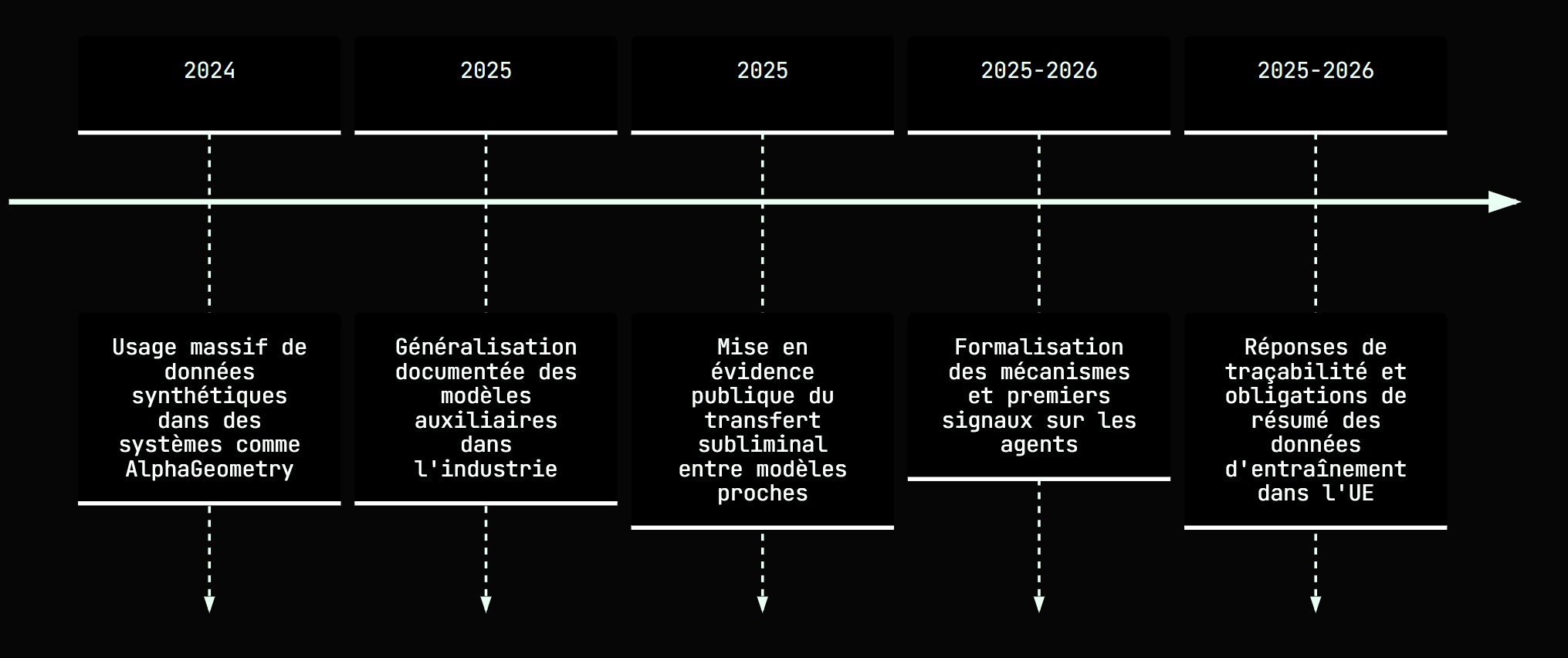
Frise construite à partir de jalons documentés par DeepMind, Microsoft Research, Anthropic, l’arXiv et la Commission européenne. [1, 3, 4, 7, 8]
Google DeepMind, de son côté, a entraîné AlphaGeometry à partir de données synthétiques [13], puis AlphaGeometry 2 sur un volume « d’un ordre de grandeur » supérieur.
Et Microsoft documente déjà des scénarios de distillation au sein d’une même lignée, par exemple de Llama 3.1 405B vers Llama 3.1 8B. [3, 4, 10, 6]
Le risque d’une monoculture mentale
Le NIST alerte sur les « monocultures algorithmiques » : quand le même modèle, ou les mêmes composants, sont réemployés à grande échelle, les défaillances deviennent corrélées.
En parallèle, un article de l’EMNLP montre que les bénéfices des données synthétiques sont conditionnels : un mélange raisonné peut aider, mais certains régimes — notamment des mélanges purement générés de type manuel scolaire — présentent des signes attendus de model collapse.
Si l’on ajoute à cette homogénéisation statistique le transfert caché de traits comportementaux, la chaîne de risque devient plus dense : même source, mêmes angles morts, mêmes dérives possibles. [5, 6, 9]
Ce qu’il faudrait exiger maintenant
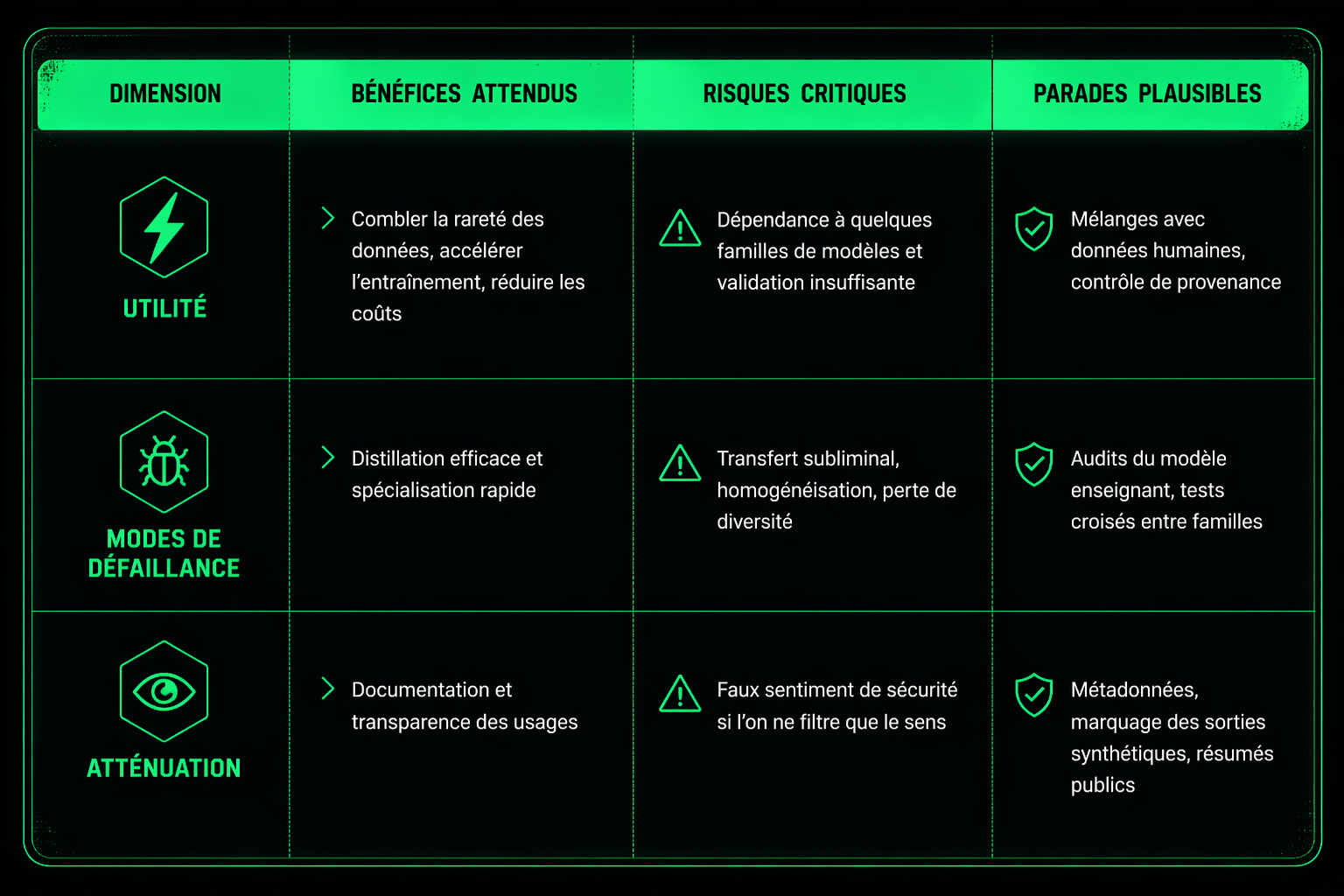
La réponse sérieuse n’est ni le rejet total des données synthétiques, ni la foi naïve dans le « corpus propre ». Elle tient en quatre exigences.
- Premièrement, tenir une provenance fine : quel modèle enseignant, quelle version, quelles consignes, quels filtres, quelles opérations de transformation.
- Deuxièmement, auditer les modèles enseignants eux-mêmes, et pas seulement les élèves.
- Troisièmement, généraliser les datasheets pour les jeux de données et les model cards pour les modèles, afin de documenter usages, limites, évaluations et contexte [18, 19].
- Quatrièmement, marquer les sorties synthétiques par métadonnées, empreintes ou filigranes quand c’est possible. [6, 9, 10]
L’alignement réglementaire existe déjà en partie. La Commission européenne impose, pour les modèles d’IA à usage général, un résumé public du contenu d’entraînement fondé sur un modèle obligatoire, incluant les données synthétiques, les sources, certains aspects du traitement, les mises à jour et les versions modifiées.
Ce n’est pas encore un bouclier complet contre le transfert subliminal, mais c’est un début de mémoire institutionnelle : nommer les sources, suivre les héritages, rendre visible ce qui, jusqu’ici, circulait dans l’ombre. [7, 11]
Dans l’économie naissante des modèles, le vrai risque n’est peut-être pas que les machines se copient. C’est qu’elles se copient mal, à bas bruit, et qu’en se transmettant leurs habitudes invisibles elles fabriquent, couche après couche, une même cécité. [1, 6, 7, 12]
Sources principales :
- [1] [2] [5] [8] [12] Subliminal Learning: Language Models Transmit Behavioral Traits via Hidden Signals in Data | Anthropic (alignment.anthropic.com)
- [3] [2604.15559] Subliminal Transfer of Unsafe Behaviors in AI Agent Distillation |arXiv (arxiv.org)
- [4] [2509.23886] Towards Understanding Subliminal Learning: When and How Hidden Biases Transfer |arXiv (arxiv.org)
- [6] [7] Examining the Expanding Role of Synthetic Data Throughout the AI Development Pipeline |Microsoft Research (microsoft.com)
- [9] Demystifying Synthetic Data in LLM Pre-training: A Systematic Study of Scaling Laws, Benefits, and Pitfalls |ACL Anthology (aclanthology.org)
- [10] Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile| NIST (nvlpubs.nist.gov)
- [11] Modèle pour les fournisseurs de modèles d’IA à usage général afin de résumer leur contenu de formation | Bâtir l’avenir numérique de l’Europe/Commission européenne (digital-strategy.ec.europa.eu)
- [13] AlphaGeometry: An Olympiad-level AI system for geometry |Google DeepMind (deepmind.google)
- [18] [1803.09010] Datasheets for Datasets | arXiv (arxiv.org)
- [19] Detecting and preventing distillation attacks | Anthropic (anthropic.com)



