OpenAI jure que son IA bat les médecins. Les études indépendantes disent l'inverse.
OpenAI affirme que sa nouvelle IA santé gratuite bat les réponses écrites par des médecins. On a regardé qui a tenu le chronomètre — et ce que les études indépendantes disent vraiment.


Une IA gratuite qui répond mieux qu'un médecin. C'est, mot pour mot, ce qu'OpenAI a annoncé ce 18 juin : sa dernière version de ChatGPT dépasserait les réponses écrites par de vrais docteurs, en précision, en clarté et en complétude.
L'annonce a fait le tour des rédactions tech en quelques heures. Le problème n'est pas que ce soit faux. C'est que le juge et l'arbitre sont la même entreprise. OpenAI a conçu le test, choisi les critères, payé les médecins évaluateurs — et n'a publié aucun résultat pour vérification externe.
Alors on fait ce que personne ne fait dans le bruit de l'annonce : on regarde qui a tenu le chronomètre, ce que mesure vraiment le test, et surtout ce que disent les études indépendantes menées en conditions réelles. Et l'écart entre les deux est vertigineux.
Dans cet article :
- Ce qu'OpenAI a réellement annoncé, chiffres à l'appui
- Pourquoi « battre les médecins » sur ce test ne veut pas dire ce que vous croyez
- Ce que trouvent les chercheurs quand l'IA santé quitte le laboratoire
- L'homme hospitalisé après un conseil diététique de ChatGPT
- Comment utiliser l'IA santé sans lui confier votre vie
Ce qu'OpenAI a vraiment claironné
Le cœur de l'annonce tient en un modèle : GPT-5.5 Instant, le moteur par défaut désormais accessible à tous les utilisateurs gratuits de ChatGPT (avec des limites d'usage). Pas une option premium réservée aux abonnés. La version que tout le monde a déjà sous la main.
Cette mise à jour gratuite n'arrive pas seule. Elle prolonge l'offensive santé d'OpenAI : ChatGPT Health, une application dédiée lancée en janvier 2026 qui se connecte à vos dossiers médicaux et à vos applis de suivi, puis « ChatGPT for Clinicians », une version réservée aux soignants. Le chatbot santé du grand public n'est qu'une pièce d'un ensemble plus large — à garder en tête, car les études citées plus bas ne testent pas toutes la même chose.
OpenAI annonce d'abord une baisse spectaculaire des erreurs. Le taux d'affirmations santé incorrectes aurait chuté de 71 % en deux mois [1], une mesure tirée de la surveillance de son propre trafic — des milliards de messages hebdomadaires passés au crible par des moniteurs automatiques.
Vient ensuite la comparaison avec les médecins, la phrase qui a fait les titres. OpenAI a demandé à des docteurs d'écrire des réponses à des conversations santé représentatives, avec un temps illimité et un accès à Internet (mais sans IA) [2].
Un panel séparé de médecins a ensuite comparé ces réponses humaines à celles du modèle, sur 3 500 réponses examinées. Le verdict d'OpenAI : GPT-5.5 Instant a été jugé supérieur aux réponses écrites par les médecins en précision, communication et complétude.
Sur ses propres tableaux de bord, le modèle gratuit dépasse à la fois GPT-4o (la génération précédente) et les réponses humaines dans les cinq catégories d'évaluation, avec un pic à 89,9 % en « suivi des instructions » [1] (sa capacité à faire exactement ce qu'on lui demande).
Le détail qui change tout : qui a fabriqué le test
Voilà le point que les titres oublient. Tous ces chiffres reposent sur HealthBench, un test maison. OpenAI l'a construit avec son propre réseau de plus de 260 médecins, à partir de grilles de notation rédigées par ces médecins plutôt que de questions de type examen [3].
✊ Posthumain n’existe que grâce aux abonnements.
Aucun algorithme. Aucune pub.
❤️ Soutenez-nous aujourd’hui et accédez immédiatement à tous les articles Premium.
C'est élégant sur le papier. Sauf qu'aucun de ces résultats n'a été publié pour une relecture extérieure. Le juge, l'arbitre et le candidat appartiennent à la même maison. Une revue spécialisée le note froidement : les affirmations reposent sur le benchmark et le réseau de médecins d'OpenAI, pas sur des tests indépendants ou évalués par des pairs.
Il existe une version clinique encore plus poussée, HealthBench Professional, dévoilée en avril. Sur ce test, la version « ChatGPT for Clinicians » (réservée aux soignants vérifiés) atteint 59,0 contre 43,7 pour les médecins humains [4] — toujours avec leur temps illimité et leur accès au web.
Le graphique ci-dessous donne la mesure de l'écart revendiqué. Gardez en tête une chose en le lisant : ces barres sortent du laboratoire d'OpenAI, pas d'un essai clinique indépendant.
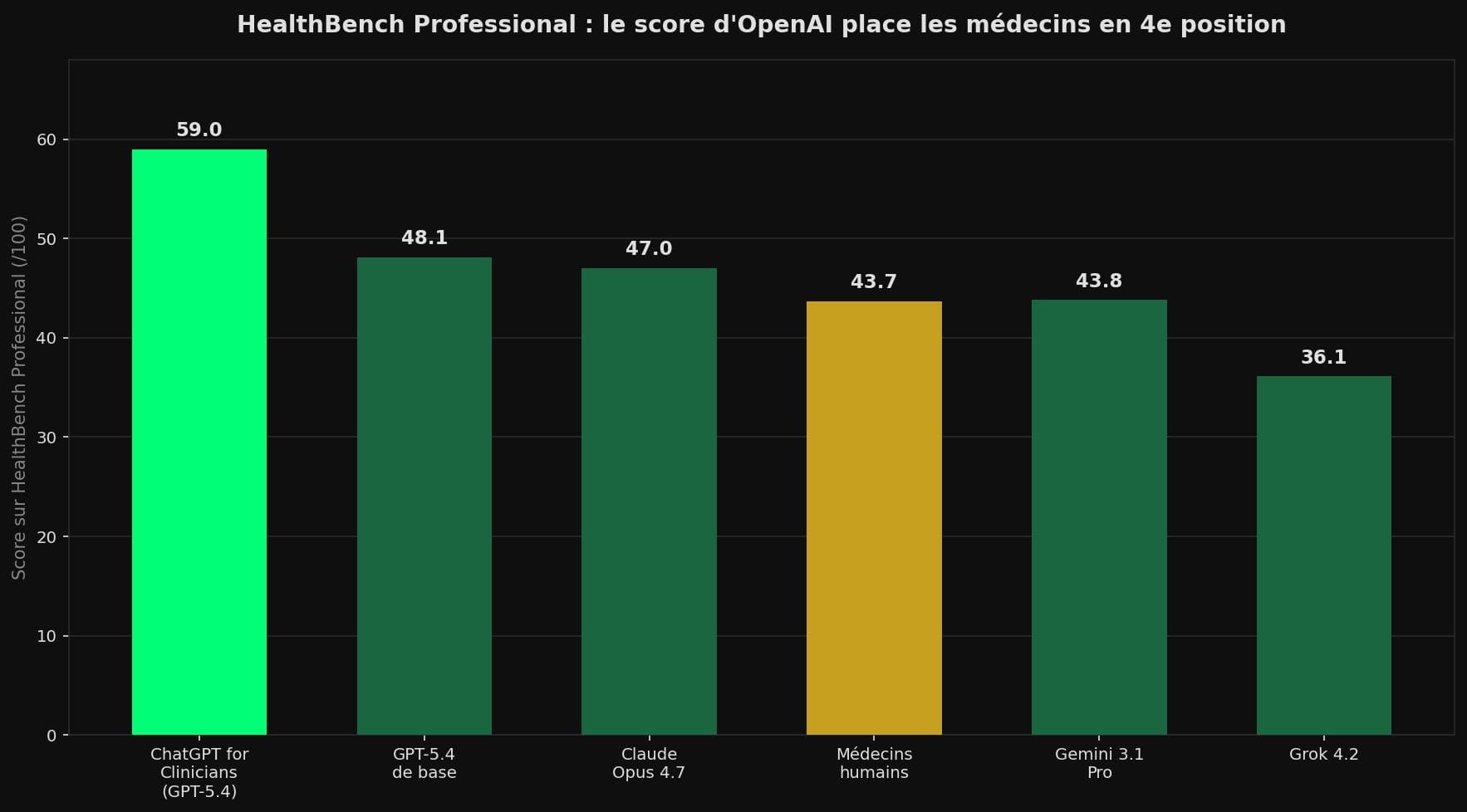
OpenAI a au moins joué franc-jeu sur la difficulté. Environ un tiers des exemples viennent de séances de « red teaming » (des médecins cherchant activement les failles du modèle), et les conversations les plus dures ont été surreprésentées par un facteur de 3,5 [5]. Le test est dur. Il reste fait maison.
Hors du labo, l'histoire se gâte
Un test maison mesure ce que son créateur a décidé de mesurer. Et c'est précisément là que des chercheurs extérieurs ont tiré la sonnette d'alarme. Une étude publiée dans Nature Medicine a fait quelque chose qu'OpenAI ne fait pas : tester l'IA avec de vrais humains, pas avec des grilles.
Le résultat est brutal. Après avoir discuté avec les chatbots, les participants n'ont identifié la bonne condition médicale qu'une fois sur trois environ, et seulement 43 % ont pris la bonne décision sur la suite à donner (urgences ou rester chez soi) [6].
Le coauteur, Andrew Bean, de l'Université d'Oxford, résume le piège : selon lui, les gens ne savent pas quelles informations ils sont censés transmettre au modèle. L'IA peut être brillante ; l'humain qui l'interroge, lui, fournit un contexte incomplet.
Son collègue Adam Mahdi, de l'Oxford Internet Institute, va plus loin. Pour lui, le décalage entre les scores de benchmark et la performance réelle devrait servir de signal d'alarme pour les régulateurs — et l'IA santé exige des tests aussi rigoureux que les essais cliniques d'un médicament.
D'autres travaux indépendants enfoncent le clou. Un audit publié dans BMJ Open a jugé « problématiques » près de la moitié des réponses santé de cinq chatbots : sur 250 réponses, 49,6 % posaient problème, dont 19,6 % « hautement problématiques » — c'est-à-dire de la désinformation pure ou des conseils potentiellement dangereux [7].
Plus inquiétant encore pour les situations graves : la première évaluation indépendante de sécurité de ChatGPT Health — menée par l'école de médecine Mount Sinai et publiée dans Nature Medicine — a constaté que l'application sous-évaluait 52 % des scénarios d'urgence médicale [8]. Acidocétose diabétique (complication aiguë et potentiellement mortelle du diabète), détresse respiratoire, douleur thoracique — souvent classées comme pouvant attendre 24 à 48 heures.
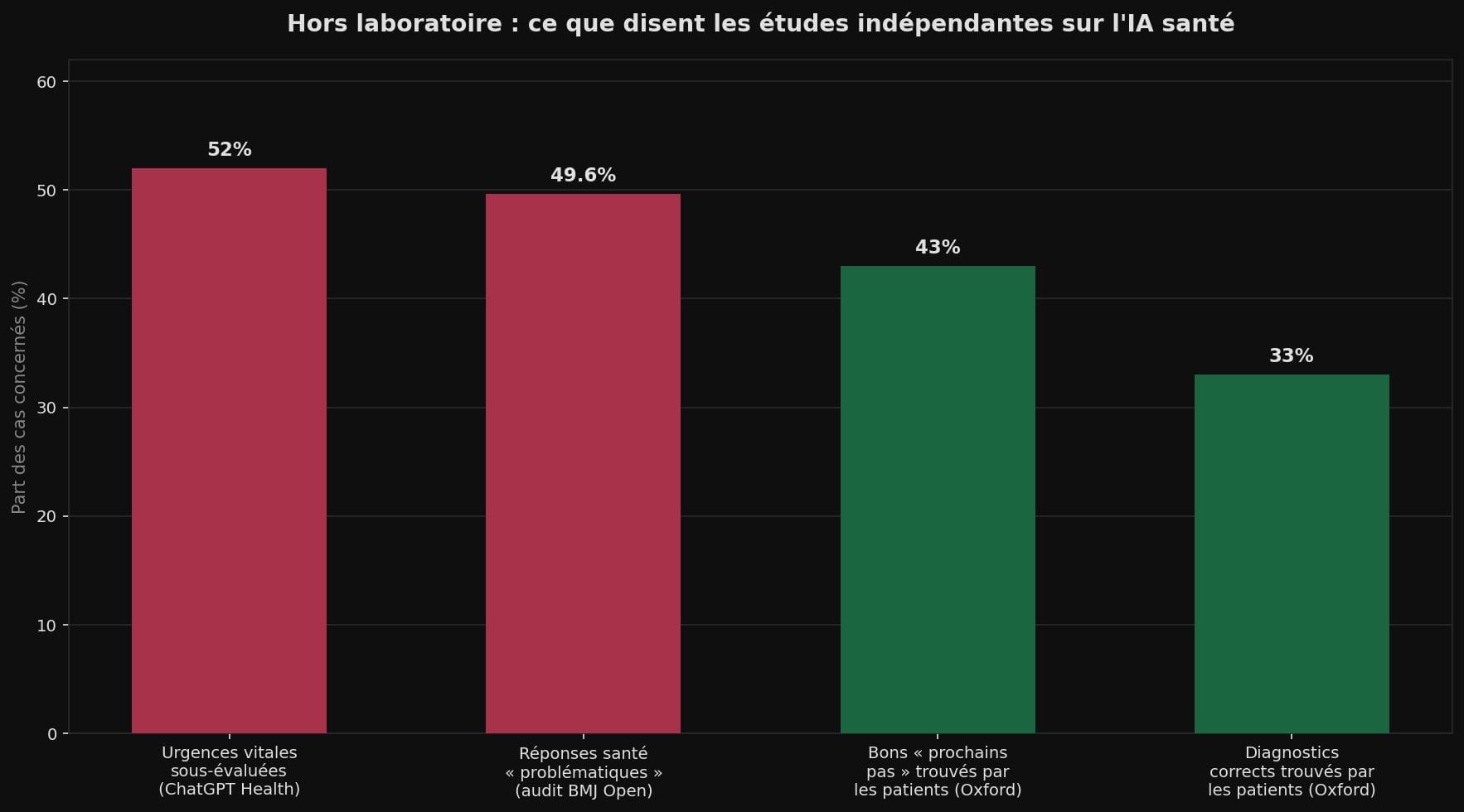
La même évaluation a constaté un déclenchement erratique des alertes vers les lignes d'aide en cas de crise suicidaire : parfois pour des situations bénignes, parfois pas du tout quand l'utilisateur décrivait un plan précis. La fiabilité, en santé, n'est pas négociable : une seule réponse dangereuse peut annuler le bénéfice de cent bonnes.
L'homme que ChatGPT a envoyé à l'hôpital
Les statistiques restent abstraites. Un cas, lui, ne s'oublie pas. En 2025, un homme de 60 ans débarque aux urgences, persuadé que son voisin l'empoisonne. Paranoïa, hallucinations, soif extrême mais peur de boire. Diagnostic : bromisme, une intoxication quasi disparue depuis un siècle [9].
L'origine ? Voulant supprimer le sel de table de son alimentation, il avait demandé à ChatGPT par quoi remplacer le chlorure. Le modèle aurait évoqué le bromure de sodium — un composé qu'on trouve dans les pesticides et les produits pour piscine. Il en a consommé pendant trois mois.
Les auteurs du cas, publié dans une revue de l'Annals of Internal Medicine, n'ont pas pu accéder à la conversation d'origine. Mais en reproduisant la requête, ils ont obtenu une réponse citant le bromure sans aucun avertissement sanitaire, et sans demander pourquoi la question était posée — ce qu'un médecin aurait fait.
Un détail compte pour rester juste : ce cas date d'avant GPT-5, et les versions récentes sont meilleures pour repérer ces drapeaux rouges. Mais il illustre le vrai danger : un ton assuré n'est pas une réponse correcte. L'IA ne savait même pas que le chlorure servait surtout à saler les plats.
Le faux procès, et le vrai enjeu
Soyons honnêtes dans les deux sens. Diaboliser ChatGPT en santé serait aussi malhonnête que le sacrer médecin-chef. Des études académiques sérieuses montrent que les modèles GPT-5 obtiennent des scores très élevés sur des questions médicales standardisées, parfois au niveau de spécialistes humains [10].
Et 230 millions de personnes posent déjà chaque semaine des questions de santé à ChatGPT — résultats de labo, préparation de rendez-vous, démêlés avec l'assurance [2]. L'usage de masse est là. Reste une seule question pratique : comment s'en servir sans se faire avoir.
Car le vrai sujet n'est pas la performance brute du modèle. C'est l'écart entre ce qu'un labo mesure et ce qui se passe quand un humain stressé, qui formule mal sa question, prend une réponse fluide pour une vérité médicale. C'est là que tout se joue.
Comment utiliser l'IA santé sans lui confier votre vie
Voilà la partie qui compte vraiment : des leviers concrets, tirés de ce que recommandent les médecins qui, eux, utilisent ces outils tous les jours. L'idée directrice tient en une phrase : l'IA prépare la consultation, elle ne la remplace pas.



